Function Notation : Evaluation
“What is the most efficient notation?” is a recurring question when I read math, machine learning, or other technical publications. Which is followed by the ...
Long story short - I needed to do some parsing of dates encoded as strings in various formats.
with the possibility that the string being parsed does not encode a date.
This is a well tread problem and one full of subtleties, so it is natural to explore how well existing libraries do. My investigation was limited to Python, but with hindsight I am curious to discard the constraint of a fixed language.
Digging a few pages into a Google search for “date parsing in Python” uncovers a variety of options and reading the package descriptions / origin story of each reveals yet more.
With some of the most popular options on the table and a list that was getting a little long we stop there. For other fun scraping related things - blog.scrapinghub - was nice source. In addition I stumbled on this blog post comparing the speed of a subset of these datetime vs Arrow vs Pendulum vs Delorean vs udatetime
2 packages that did not make the cut for arbitrary reasons :
To test the various packages I needed to define
A common API across the packages.
Quality measures that are informed by how I will use the package (now and in the future).
Datasets used to generate these performance measures.
For each package I was interested in the following 3 measures
Precision : What percent of strings return the correct DateTime if the string does encode a date or return None if the string does not encode a date.
Recall : Of the strings that do encode dates - how many get parsed to the correct DateTime?
Runtime : What is the mean runtime per input string?
To generate quality metrics we require testing data. I considered one dataset of actual dates encoded in various standard and non-standard ways and multiple datasets of random strings that were not intended to represent dates.
A hand constructed list of string encodings of dates and associated true date.
Random Shorts : Uniform random integers from -32767 to 32768
Random Double : Uniform random doubles from 0.0 to 1.0
Single characters [a-z] and [A-Z]
The data is a hand generated list of various date formats I have observed in the wild, some formats and garblings that plausibly occur, and for each the associated standard ISO-8601 formatting.
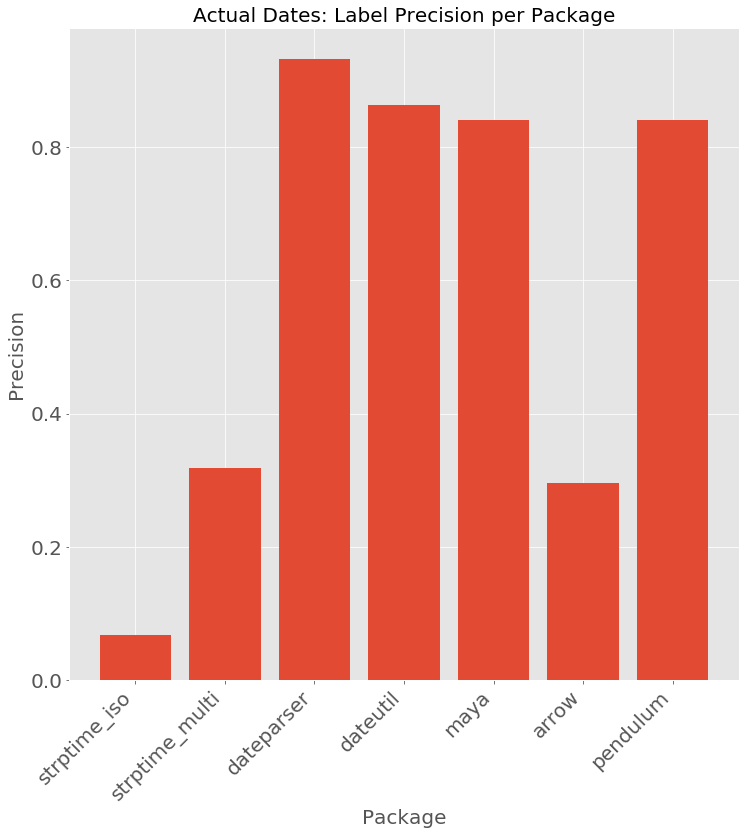
Dateparser has the highest recall of the bunch. The gap between dateparser and the others would be even larger if the evaluation covered more languages or other specialties of dateparser. The only 3 dates that dateparser struggled with were
20110101 -> 1010-02-01 01:00:00 : ISO-8601 order without delimitersJanuaty 1 2011 -> None : A MispellingFirst Friday of January 2011 -> None : Purposefully trickymaya / pendulum and dateutil have comparable performance with the same 6 unsurprising errors.
2011|01|01 -> None2011_01_01 -> NoneJanuaty 1 2011 -> NoneFirst Friday of January 2011 -> None2011/25/06 -> None2011年1月1日 -> Nonemaya and pendulum though give a surprising result
2011-1-1 -> 2011-11-01While it is not apparent that Arrow is designed for high recall - it performs similar to multiple passes of datetime.strptime with different patterns.
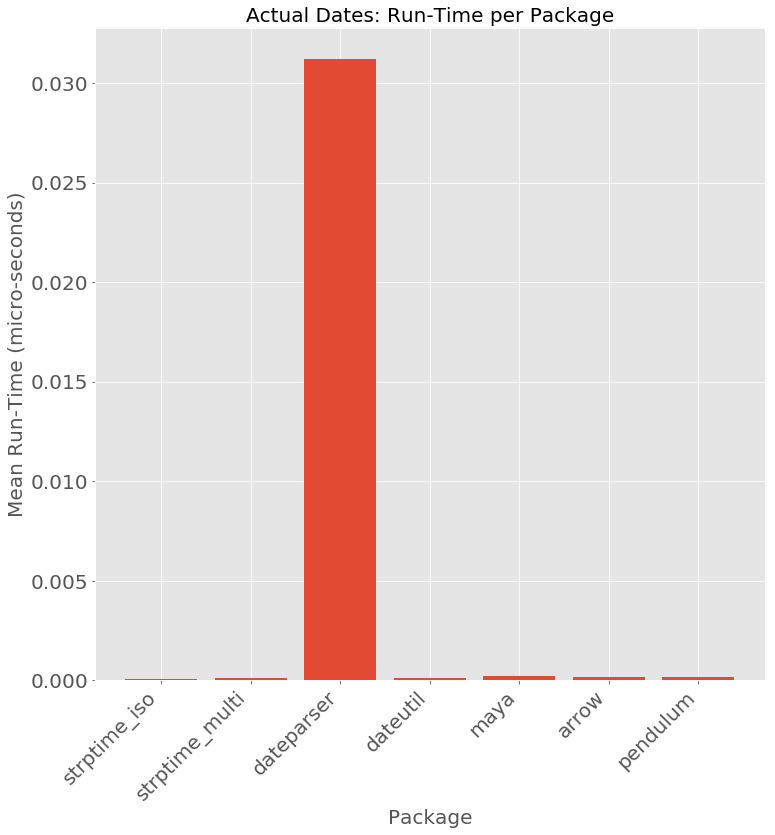
There is definitely a cost for dateparser’s performance - requiring roughly 100 times the time per input string.
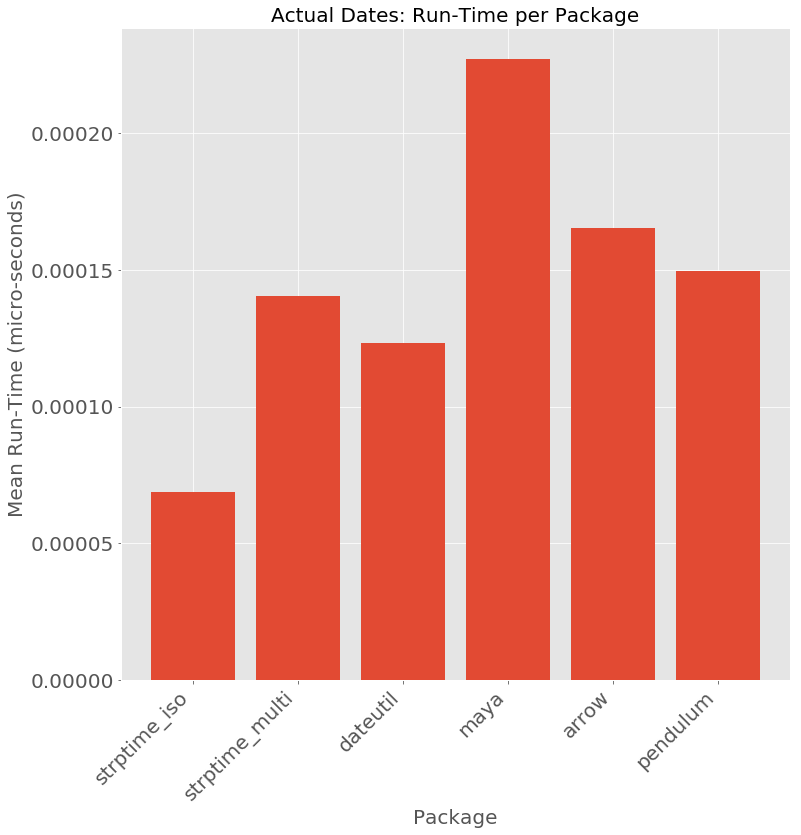
Filtering out that outlier to zoom in - we find that amongst medium recall dateutil has the best performance.
After the preliminary tests strings that did encode dates and the exciting results from dateparser - I delved into tests on performance on non-date strings. The first example of such garbage inputs is random integers from -32767 to 32768.
def generate_test_short_data(sample_size = 100):
return [(str(random.randint(-32767, 32768)), None, "Random Short") for i in range(sample_size)]

Perhaps unsurprisingly the parsers that are more flexible and have higher recall have a higher tendency of parsing random input data as a date. This leads to a large drops in precision for dateparser, dateutil, maya, and pendulum. dateutil / maya / pendulum share the same errors parsing 4 digit integers as years. Dateparser parses both 4 digit integers as YYYY and when feasible parses 5 digit integers as MDYYH or MDDYY. The precision numbers for dateutil / maya / pendulum are entirely determined by the range of values considered, since for under 10000 the string gets parsed as a year and over 10000 is not parsed to a date.
-4656 -> 4656-10-22 00:00:009094 -> 9094-10-22 00:00:0020641 -> 2041-02-06 00:00:0010363 -> 2063-10-03 00:00:007394 -> 7394-10-22 00:00:00-4656 -> 4656-10-22 00:00:009094 -> 9094-10-22 00:00:007394 -> 7394-10-22 00:00:00-925 -> 0925-10-22 00:00:005371 -> 5371-10-22 00:00:00-4656 -> 1969-12-31 22:42:249094 -> 1970-01-01 02:31:34-17267 -> 1969-12-31 19:12:13-20830 -> 1969-12-31 18:12:5020641 -> 1970-01-01 05:44:01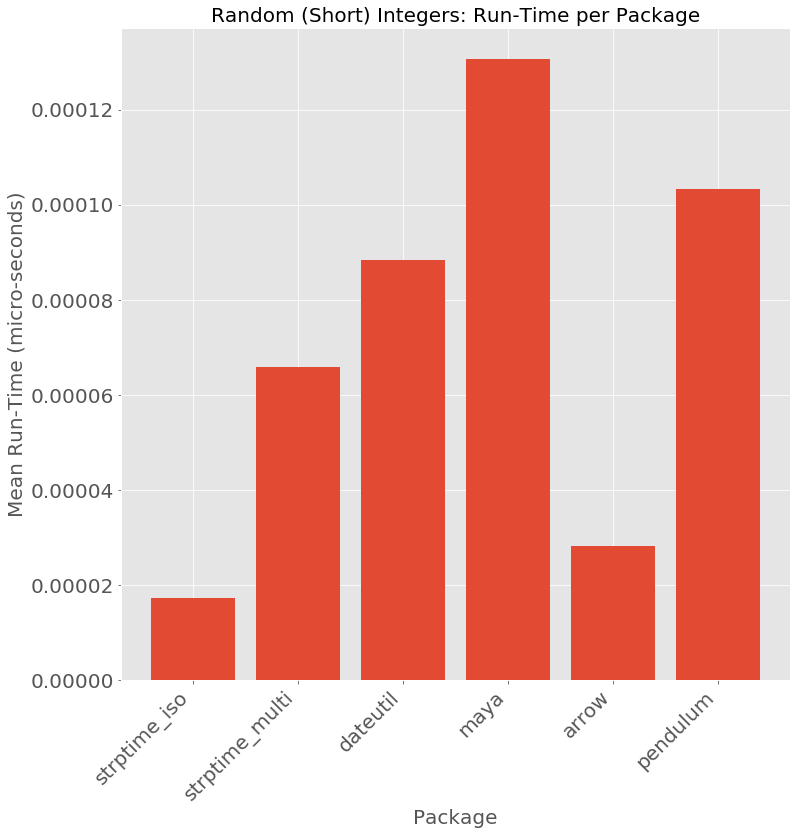
Dataparser clocked in at 0.16 microseconds per string - which is roughly 5x the run-time as the date strings above and up to 1000 times larger than the other packages.
dateparser has a range of behaviors on integers depending on the size of the input. From 1-100 it looks to try parsing as a month, then a day, then year 19xx or 20xx where the other fields are filled in using the current time. From 100 to 1000 it parses as a time of day. From 1000 to 10000 it parses the full integer as a year. Beyond 10000 it jumps into the behavior mentioned above.
The second trivial experiment
![Single Characters [A-Z][a-z] : Precision](/images/char_prec.png)
Most packages nail random strings. There are many single characters though that dateparser maps to a datetime. I expect these derive from shorthand for days of the week (English : M,T,W,..) in other langauges.
a -> 2017-01-09 00:00:00d -> 2017-10-08 00:00:00h -> 2017-10-09 00:00:00j -> 2017-10-05 00:00:00k -> 2017-10-03 00:00:00l -> 2017-10-02 00:00:00m -> 2017-10-09 00:00:00s -> 2017-10-07 00:00:00v -> 2017-10-06 00:00:00A -> 2017-01-09 00:00:00![Single Characters [A-Z][a-z] : Run-Time 2](/images/char_time.png)
def generate_test_double_data(sample_size = 100):
return [(str(100.0 * np.random.rand()), None, "Random Double") for i in range(sample_size)]
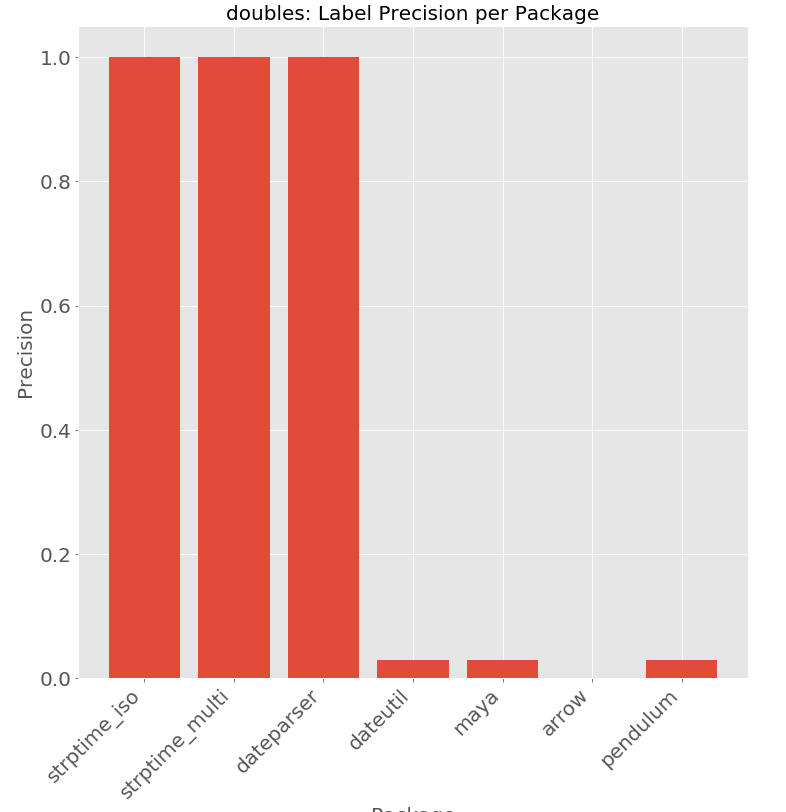
37.18858554492067 -> 2037-10-09 00:00:0090.58570851440683 -> 1990-10-09 00:00:0089.55455036895947 -> 1989-10-09 00:00:0099.18829981896567 -> 1999-10-09 00:00:0063.12637119966145 -> 2063-10-09 00:00:00Example False Positives for arrow ————————————–
30.628229006528297 -> 1970-01-01 00:00:30.62822951.9091657471709 -> 1970-01-01 00:00:51.90916621.439205229372703 -> 1970-01-01 00:00:21.43920578.72487521117215 -> 1970-01-01 00:01:18.72487584.81257902971872 -> 1970-01-01 00:01:24.812579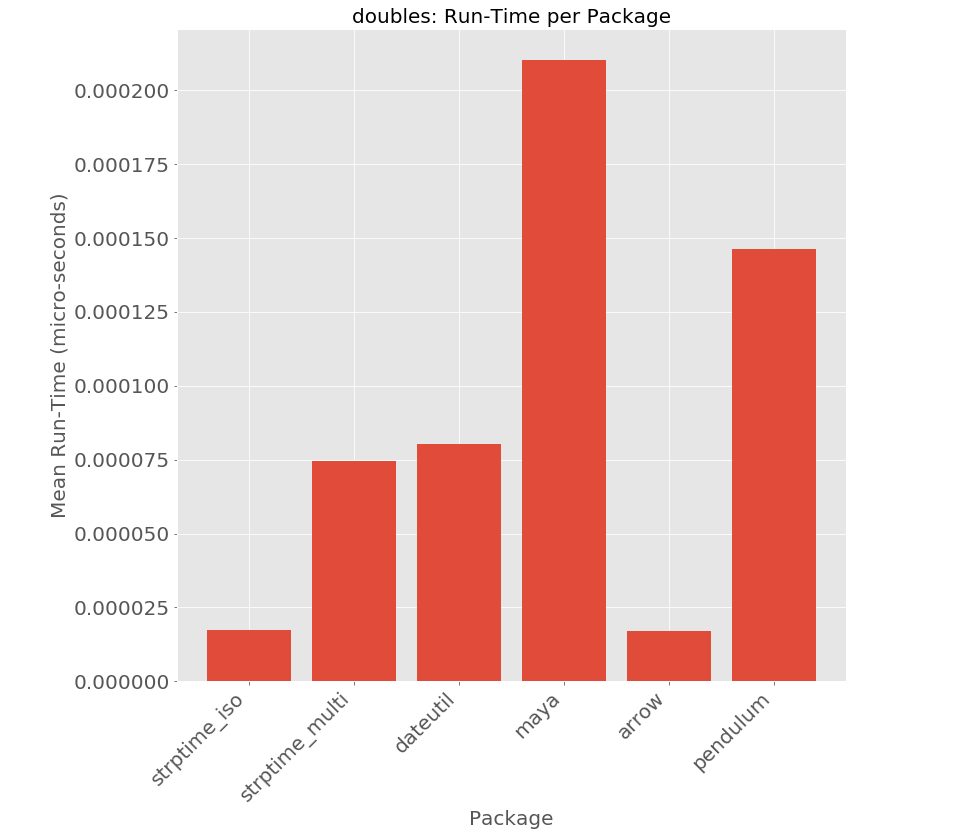
The best tool depends heavily on the job. In this case it depends on your degree of certainty that the strings you are parsing are truly dates and the cost if you are wrong.
If recall is your top priority (or if you can guarantee each string does represent a data) and time is not critical -> dateparser.
If there is only a handful of formats that you can infer at the start -> strptime.
dateutil / maya / pendulum are in the middle ground where you need to be flexible to different formats but there may be non-date strings. These have very similar precision and run-time, but dateutil is often a little bit faster and more correct.
For my purposes - I will be using dateutil wrapped with a check for whether the string can be cast as a float.
“What is the most efficient notation?” is a recurring question when I read math, machine learning, or other technical publications. Which is followed by the ...
These are quick notes on convolutions, their generalizations, and their relationship to Fourier transforms.
Coordinates. A word so common that I rarely (perhaps never) consider how it is defined. In the following I browse common definitions & their ambiguity, p...
One of my first exposures to the art of proof was proving the uniqueness of the additive identity. At the convergence of thoughts about algebraic structures ...
In this digression into the topic of symmetries in Machine Learning we
Recently was able to experience the joy of setting up Jekyll and Github Pages in more detail through setting up an internal documentation hub at work.
Topics: Tools for analyzing and modifying binary files. (cmp, dd, xxd) Inferring the format of binary files.
I recently started a review of Abstract Algebra with primary focus on Groups. This resulted in a deeper dive into the properties of quotients and Normal sub...
A nearly complete fragment of a paper on Loop Quantum Cosmology identifying a simple form of Hamiltonian constraint operator for Bianchi I.
As much as I prefer nearly any other language to Bash (or other Shell scripting) time and again I find myself scripting in Bash.
In lazily paging through Cormen et al I noticed that I have never seriously thought about the mathematical properties of the asymptotic notations used in ana...
Long story short - I needed to do some parsing of dates encoded as strings in various formats.
This is a mathematical digression into statistical inference on the circle. This is motivated by a strange mix of things :
Notation is powerful
State Space Modeling